gcr.io域名仓库里的。域名/库名/img_name:tag这种形式,dockerhub上要拉取镜像直接是库名/img_name:tag这种名字,是因为域名缺省是docker.io也就是dockerhub上看到的都是这个域名仓库的gcr.io/google_containers这些镜像,etcd数据库里,apiserver去和etcd交互,其他组件和apiserver交互,kubelet调用api去操作docker,其中一些组件也会去操作各个节点的系统设置
三个master,多个node。
etcd
kube-apiserver
kube-controller-manager
kube-scheduler
kubelet
kube-proxy
docker
nginx
kubelet
kube-proxy
docker
nginx
hosts统一如下CentOS 7.6+以上,最好不要使用centos7.5以下,容器技术依赖于内核技术,低版本系统部署和运行后可能问题会非常多。
1 2 3 4 5 6 7 8 9 cat /etc/hosts 127.0.0.1 apiserver.k8s.local 192.168.33.101 master01 192.168.33.102 master02 192.168.33.103 master03 192.168.33.201 node01 192.168.33.202 node02 192.168.33.203 node03
IP
Hostname
内核
CPU
Memory
192.168.33.101
master01
3.10.0-1062
2
4G
192.168.33.102
master02
3.10.0-1062
2
4G
192.168.33.103
master03
3.10.0-1062
2
4G
192.168.33.201
node01
3.10.0-1062
2
4G
192.168.33.202
node02
3.10.0-1062
2
4G
192.168.33.203
node03
3.10.0-1062
2
4G
kubeadm好像要求最低配置2c2g还是多少来着,越高越好
所有操作全部用root使用者进行,系统盘根目录一定要大,不然到时候镜像多了例如到了85%会被gc回收镜像
高可用一般建议大于等于3台的奇数台,使用3台master来做高可用
导入升级内核的yum源
1 2 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
查看可用版本 kernel-lt指长期稳定版 kernel-ml指最新版
1 yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
安装kernel-ml
1 yum --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel -y
查看系统上的所有可用内核
1 awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
1 grub2-set-default 'CentOS Linux (5.7.7-1.el7.elrepo.x86_64) 7 (Core)'
1 grub2-mkconfig -o /boot/grub2/grub.cfg
1 2 3 4 5 6 7 8 9 10 #关闭防火墙 systemctl disable --now firewalld NetworkManager #关闭swap swapoff -a sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab #关闭selinux setenforce 0 sed -ri '/^[^#]*SELINUX=/s#=.+$#=disabled#' /etc/selinux/config
1 2 3 yum install epel-release -y yum update -y
1 yum -y install gcc bc gcc-c++ ncurses ncurses-devel cmake elfutils-libelf-devel openssl-devel flex* bison* autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake pcre pcre-devel openssl openssl-devel jemalloc-devel tlc libtool vim unzip wget lrzsz bash-comp* ipvsadm ipset jq sysstat conntrack libseccomp conntrack-tools socat curl wget git conntrack-tools psmisc nfs-utils tree bash-completion conntrack libseccomp net-tools crontabs sysstat iftop nload strace bind-utils tcpdump htop telnet lsof
内核4.19及4.19以上的用这个ipvs配置文件
1 2 3 4 5 6 7 8 9 10 11 12 :> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done
1 2 3 4 5 6 7 8 9 10 11 12 :> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack_ipv4 br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done
1 2 systemctl daemon-reload systemctl enable --now systemd-modules-load.service
1 2 3 4 5 6 7 $ lsmod | grep ip_vs ip_vs_sh 12688 0 ip_vs_wrr 12697 0 ip_vs_rr 12600 11 ip_vs 145497 17 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 133095 7 ip_vs,nf_nat,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_netlink,nf_conntrack_ipv4 libcrc32c 12644 3 ip_vs,nf_nat,nf_conntrack
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 cat <<EOF > /etc/sysctl.d/k8s.conf net.ipv6.conf.all.disable_ipv6 = 1 #禁用ipv6 net.ipv6.conf.default.disable_ipv6 = 1 #禁用ipv6 net.ipv6.conf.lo.disable_ipv6 = 1 #禁用ipv6 net.ipv4.neigh.default.gc_stale_time = 120 #决定检查过期多久邻居条目 net.ipv4.conf.all.rp_filter = 0 #关闭反向路由校验 net.ipv4.conf.default.rp_filter = 0 #关闭反向路由校验 net.ipv4.conf.default.arp_announce = 2 #始终使用与目标IP地址对应的最佳本地IP地址作为ARP请求的源IP地址 net.ipv4.conf.lo.arp_announce = 2 #始终使用与目标IP地址对应的最佳本地IP地址作为ARP请求的源IP地址 net.ipv4.conf.all.arp_announce = 2 #始终使用与目标IP地址对应的最佳本地IP地址作为ARP请求的源IP地址 net.ipv4.ip_forward = 1 #启用ip转发功能 net.ipv4.tcp_max_tw_buckets = 5000 #表示系统同时保持TIME_WAIT套接字的最大数量 net.ipv4.tcp_syncookies = 1 #表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理 net.ipv4.tcp_max_syn_backlog = 1024 #接受SYN同包的最大客户端数量 net.ipv4.tcp_synack_retries = 2 #活动TCP连接重传次数 net.bridge.bridge-nf-call-ip6tables = 1 #要求iptables对bridge的数据进行处理 net.bridge.bridge-nf-call-iptables = 1 #要求iptables对bridge的数据进行处理 net.bridge.bridge-nf-call-arptables = 1 #要求iptables对bridge的数据进行处理 net.netfilter.nf_conntrack_max = 2310720 #修改最大连接数 fs.inotify.max_user_watches=89100 #同一用户同时可以添加的watch数目 fs.may_detach_mounts = 1 #允许文件卸载 fs.file-max = 52706963 #系统级别的能够打开的文件句柄的数量 fs.nr_open = 52706963 #单个进程可分配的最大文件数 vm.overcommit_memory=1 #表示内核允许分配所有的物理内存,而不管当前的内存状态如何 vm.panic_on_oom=0 #内核将检查是否有足够的可用内存供应用进程使用 vm.swappiness = 0 #关注swap net.ipv4.tcp_keepalive_time = 600 #修复ipvs模式下长连接timeout问题,小于900即可 net.ipv4.tcp_keepalive_intvl = 30 #探测没有确认时,重新发送探测的频度 net.ipv4.tcp_keepalive_probes = 10 #在认定连接失效之前,发送多少个TCP的keepalive探测包 vm.max_map_count=262144 #定义了一个进程能拥有的最多的内存区域 EOF sysctl --system
1 2 3 4 5 6 7 8 9 10 cat>/etc/security/limits.d/kubernetes.conf<<EOF * soft nproc 131072 * hard nproc 131072 * soft nofile 131072 * hard nofile 131072 root soft nproc 131072 root hard nproc 131072 root soft nofile 131072 root hard nofile 131072 EOF
1 cd /etc/yum.repos.d/ && wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
(RHEL7/CentOS7: User namespaces disabled; add 'user_namespace.enable=1' to boot command line)
1 2 3 4 grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)" #然后重启 reboot
1 yum install docker-ce -y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/ mkdir -p /etc/docker/ cat > /etc/docker/daemon.json <<EOF { "log-driver": "json-file", "exec-opts": ["native.cgroupdriver=systemd"], "log-opts": { "max-size": "100m", "max-file": "3" }, "live-restore": true, "max-concurrent-downloads": 10, "max-concurrent-uploads": 10, "registry-mirrors": ["https://2lefsjdg.mirror.aliyuncs.com"], "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ] } EOF
1 systemctl enable --now docker
1 2 3 4 5 6 7 cat <<EOF >/etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 EOF
1 2 3 4 5 6 yum install -y \ kubeadm-1.18.5 \ kubectl-1.18.5 \ kubelet-1.18.5 \ --disableexcludes=kubernetes && \ systemctl enable kubelet
1 2 3 4 5 yum install -y \ kubeadm-1.18.5 \ kubelet-1.18.5 \ --disableexcludes=kubernetes && \ systemctl enable kubelet
1 mkdir -p /etc/kubernetes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 cat > /etc/kubernetes/nginx.conf << EOF user nginx nginx; worker_processes auto; events { worker_connections 20240; use epoll; } error_log /var/log/nginx_error.log info; stream { upstream kube-servers { hash $remote_addr consistent; server master01:6443 weight=5 max_fails=1 fail_timeout=3s; server master02:6443 weight=5 max_fails=1 fail_timeout=3s; server master03:6443 weight=5 max_fails=1 fail_timeout=3s; } server { listen 8443 reuseport; proxy_connect_timeout 3s; proxy_timeout 3000s; proxy_pass kube-servers; } } EOF
1 2 3 4 5 6 7 docker run --restart=always \ -v /etc/kubernetes/nginx.conf:/etc/nginx/nginx.conf \ -v /etc/localtime:/etc/localtime:ro \ --name k8sHA \ --net host \ -d \ nginx
1 2 3 4 wget https://github.com/21ki/kubernetes/releases/download/v1.19.1/kubeadm-v1.19.1.zip unzip kubeadm-v1.19.1.zip chmod +x kubeadm mv -f kubeadm /usr/bin/kubeadm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 cat > /root/initconfig.yaml << EOF apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration imageRepository: registry.aliyuncs.com/k8sxio kubernetesVersion: v1.18.5 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes networking: dnsDomain: cluster.local serviceSubnet: 169.0.0.0/12 podSubnet: 10.0.0.0/8 ##Cilium的pod段 controlPlaneEndpoint: apiserver.k8s.local:8443 apiServer: timeoutForControlPlane: 4m0s extraArgs: authorization-mode: "Node,RBAC" enable-admission-plugins: "NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeClaimResize,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,Priority,PodPreset" runtime-config: api/all=true,settings.k8s.io/v1alpha1=true storage-backend: etcd3 etcd-servers: https://192.168.33.101:2379,https://192.168.33.102:2379,https://192.168.33.103:2379 #修改对应的ip certSANs: - 10.96.0.1 - 127.0.0.1 - localhost - apiserver.k8s.local - 192.168.33.101 #修改对应的ip - 192.168.33.102 #修改对应的ip - 192.168.33.103 #修改对应的ip - master01 #修改对应的hostname - master02 #修改对应的hostname - master03 #修改对应的hostname - master - kubernetes - kubernetes.default - kubernetes.default.svc - kubernetes.default.svc.cluster.local extraVolumes: - hostPath: /etc/localtime mountPath: /etc/localtime name: localtime readOnly: true controllerManager: extraArgs: bind-address: "0.0.0.0" experimental-cluster-signing-duration: 867000h extraVolumes: - hostPath: /etc/localtime mountPath: /etc/localtime name: localtime readOnly: true scheduler: extraArgs: bind-address: "0.0.0.0" extraVolumes: - hostPath: /etc/localtime mountPath: /etc/localtime name: localtime readOnly: true dns: type: CoreDNS imageRepository: registry.aliyuncs.com/k8sxio imageTag: 1.7.0 etcd: local: imageRepository: registry.aliyuncs.com/k8sxio imageTag: 3.4.7 dataDir: /var/lib/etcd serverCertSANs: - master - 192.168.33.101 #修改对应的ip - 192.168.33.102 #修改对应的ip - 192.168.33.103 #修改对应的ip - master01 #修改对应的hostname - master02 #修改对应的hostname - master03 #修改对应的hostname peerCertSANs: - master - 192.168.33.101 #修改对应的ip - 192.168.33.102 #修改对应的ip - 192.168.33.103 #修改对应的ip - master01 #修改对应的hostname - master02 #修改对应的hostname - master03 #修改对应的hostname extraArgs: auto-compaction-retention: "1h" max-request-bytes: "33554432" quota-backend-bytes: "8589934592" enable-v2: "false" --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs ipvs: excludeCIDRs: null minSyncPeriod: 0s scheduler: "rr" strictARP: false syncPeriod: 15s iptables: masqueradeAll: true masqueradeBit: 14 minSyncPeriod: 0s syncPeriod: 30s --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: "systemd" failSwapOn: true EOF
warning,错误的话会抛出error,没错则会输出到包含字符串kubeadm join xxx啥的
1 kubeadm init --config /root/initconfig.yaml --dry-run
1 kubeadm config images pull --config /root/initconfig.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 kubeadm init --config /root/initconfig.yaml --upload-certs ... ... ... You can now join any number of the control-plane node running the following command on each as root: kubeadm join apiserver.k8s.local:8443 --token 8lmdqu.cqe8r0rxa0056vmm \ --discovery-token-ca-cert-hash sha256:5ca87fff6b414a0872ab5452972d7e36e4bad7ab3a0bc385abe0138ce671eabb \ --control-plane --certificate-key 7a1d432b2834464a82fd7cba0e9e5d8409c492cf9a4ee6328fb4f84b6a78934a Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join apiserver.k8s.local:8443 --token 8lmdqu.cqe8r0rxa0056vmm \ --discovery-token-ca-cert-hash sha256:5ca87fff6b414a0872ab5452972d7e36e4bad7ab3a0bc385abe0138ce671eabb
~/.kube/config
1 2 3 4 5 mkdir -p $HOME/.kube sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
1 kubectl -n kube-system get cm kubeadm-config -o yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 cat > /root/healthz-rbac.yml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: healthz-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: healthz-reader subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:authenticated - apiGroup: rbac.authorization.k8s.io kind: Group name: system:unauthenticated --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: healthz-reader rules: - nonResourceURLs: ["/healthz", "/healthz/*"] verbs: ["get", "post"] EOF
1 kubectl apply -f /root/healthz-rbac.yml
将master01上的配置文件发到其他2个master节点上
1 2 3 4 5 6 7 8 for node in 192.168.33.102 192.168.33.103;do ssh $node 'mkdir -p /etc/kubernetes/pki/etcd' scp -r /root/initconfig.yaml $node:/root/initconfig.yaml scp -r /etc/kubernetes/pki/ca.* $node:/etc/kubernetes/pki/ scp -r /etc/kubernetes/pki/sa.* $node:/etc/kubernetes/pki/ scp -r /etc/kubernetes/pki/front-proxy-ca.* $node:/etc/kubernetes/pki/ scp -r /etc/kubernetes/pki/etcd/ca.* $node:/etc/kubernetes/pki/etcd/ done
先拉取镜像
1 kubeadm config images pull --config /root/initconfig.yaml
查看master01上 带有--control-plane的那一行
1 2 3 kubeadm join apiserver.k8s.local:8443 --token 8lmdqu.cqe8r0rxa0056vmm \ --discovery-token-ca-cert-hash sha256:5ca87fff6b414a0872ab5452972d7e36e4bad7ab3a0bc385abe0138ce671eabb \ --control-plane --certificate-key 7a1d432b2834464a82fd7cba0e9e5d8409c492cf9a4ee6328fb4f84b6a78934a
1 2 3 4 5 mkdir -p $HOME/.kube sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
1 2 3 4 5 yum -y install bash-comp* source <(kubectl completion bash) echo 'source <(kubectl completion bash)' >> ~/.bashrc
1 docker cp `docker ps -a | awk '/k8s_etcd/{print $1}'|head -n1`:/usr/local/bin/etcdctl /usr/local/bin/etcdctl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat >/etc/profile.d/etcd.sh<<'EOF' ETCD_CERET_DIR=/etc/kubernetes/pki/etcd/ ETCD_CA_FILE=ca.crt ETCD_KEY_FILE=healthcheck-client.key ETCD_CERT_FILE=healthcheck-client.crt ETCD_EP=https://192.168.33.101:2379,https://192.168.33.102:2379,https://192.168.33.103:2379 alias etcd_v3="ETCDCTL_API=3 \ etcdctl \ --cert ${ETCD_CERET_DIR}/${ETCD_CERT_FILE} \ --key ${ETCD_CERET_DIR}/${ETCD_KEY_FILE} \ --cacert ${ETCD_CERET_DIR}/${ETCD_CA_FILE} \ --endpoints $ETCD_EP" EOF
1 source /etc/profile.d/etcd.sh
1 2 3 4 5 6 7 8 9 etcd_v3 endpoint status --write-out=table +-----------------------------+------------------+---------+---------+-----------+-----------+------------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX | +-----------------------------+------------------+---------+---------+-----------+-----------+------------+ | https://192.168.33.101:2379 | c724c500884441af | 3.4.7 | 1.6 MB | true | 7 | 1865 | | https://192.168.33.102:2379 | 3dcceec24ad5c5d4 | 3.4.7 | 1.6 MB | false | 7 | 1865 | | https://192.168.33.103:2379 | bc21062efb4a5d4c | 3.4.7 | 1.5 MB | false | 7 | 1865 | +-----------------------------+------------------+---------+---------+-----------+-----------+------------+
1 2 3 4 5 6 7 8 etcd_v3 endpoint health --write-out=table +-----------------------------+--------+-------------+-------+ | ENDPOINT | HEALTH | TOOK | ERROR | +-----------------------------+--------+-------------+-------+ | https://192.168.33.103:2379 | true | 19.288026ms | | | https://192.168.33.102:2379 | true | 19.2603ms | | | https://192.168.33.101:2379 | true | 22.490443ms | | +-----------------------------+--------+-------------+-------+
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 mkdir -p /opt/etcd cat>/opt/etcd/etcd_cron.sh<<'EOF' #!/bin/bash set -e source /etc/profile export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin master=`ETCDCTL_API=3 etcdctl --endpoints="https://192.168.33.101:2379,https://192.168.33.102:2379,https://192.168.33.103:2379" --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt endpoint status | grep true|awk -F"," '{print $1}'` : ${bak_dir:=/root/} #缺省备份目录,可以修改成存在的目录 : ${cert_dir:=/etc/kubernetes/pki/etcd/} : ${endpoints:=$master} bak_prefix='etcd-' cmd_suffix='date +%Y-%m-%d-%H-%M' bak_suffix='.db' #将规范化后的命令行参数分配至位置参数($1,$2,...) temp=`getopt -n $0 -o c:d: -u -- "$@"` [ $? != 0 ] && { echo ' Examples: # just save once bash $0 /tmp/etcd.db # save in contab and keep 5 bash $0 -c 5 ' exit 1 } set -- $temp # -c 备份保留副本数量 # -d 指定备份存放目录 while true;do case "$1" in -c) [ -z "$bak_count" ] && bak_count=$2 printf -v null %d "$bak_count" &>/dev/null || \ { echo 'the value of the -c must be number';exit 1; } shift 2 ;; -d) [ ! -d "$2" ] && mkdir -p $2 bak_dir=$2 shift 2 ;; *) [[ -z "$1" || "$1" == '--' ]] && { shift;break; } echo "Internal error!" exit 1 ;; esac done etcd::cron::save(){ cd $bak_dir/ ETCDCTL_API=3 etcdctl --endpoints=$endpoints --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt snapshot save $bak_prefix$($cmd_suffix)$bak_suffix rm_files=`ls -t $bak_prefix*$bak_suffix | tail -n +$[bak_count+1]` if [ -n "$rm_files" ];then rm -f $rm_files fi } main(){ [ -n "$bak_count" ] && etcd::cron::save || etcd_v3 snapshot save $@ } main $@ EOF
1 0 0 * * * bash /opt/etcd/etcd_cron.sh -c 4 -d /opt/etcd/ &>/dev/null
--control-plane
1 2 kubeadm join apiserver.k8s.local:8443 --token 8lmdqu.cqe8r0rxa0056vmm \ --discovery-token-ca-cert-hash sha256:5ca87fff6b414a0872ab5452972d7e36e4bad7ab3a0bc385abe0138ce671eabb
node-role.kubernetes.io/xxxx
1 2 3 4 5 6 7 8 [root@master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 NotReady master 17m v1.18.5 master02 NotReady master 14m v1.18.5 master03 NotReady master 13m v1.18.5 node01 NotReady <none> 24s v1.18.5 node02 NotReady <none> 18s v1.18.5 node03 NotReady <none> 11s v1.18.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master01 ~]# kubectl label node node01 node-role.kubernetes.io/node="" node/node01 labeled [root@master01 ~]# kubectl label node node02 node-role.kubernetes.io/node="" node/node02 labeled [root@master01 ~]# kubectl label node node03 node-role.kubernetes.io/node="" node/node03 labeled [root@master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 NotReady master 25m v1.18.5 master02 NotReady master 22m v1.18.5 master03 NotReady master 21m v1.18.5 node01 NotReady node 8m v1.18.5 node02 NotReady node 7m54s v1.18.5 node03 NotReady node 7m47s v1.18.5
1 https://github.com/helm/helm/releases
链接: [https://pan.baidu.com/s/13qsdwCzaKfnZNlDarsBYpg](https://pan.baidu.com/s/13qsdwCzaKfnZNlDarsBYpg) 提取码: wu22
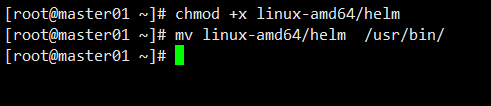
1 tar xvf helm-v3.3.0-rc.1-linux-amd64.tar
1 2 chmod +x linux-amd64/helm mv linux-amd64/helm /usr/bin/
1 https://github.com/cilium/cilium
1 helm repo add cilium https://helm.cilium.io
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 helm install cilium cilium/cilium --version 1.8.1 \ --namespace kube-system \ --set global.nodeinit.enabled=true \ --set global.externalIPs.enabled=true \ --set global.nodePort.enabled=true \ --set global.hostPort.enabled=true \ --set global.pullPolicy=IfNotPresent \ --set config.ipam=cluster-pool \ --set global.hubble.enabled=true \ --set global.hubble.listenAddress=":4244" \ --set global.hubble.relay.enabled=true \ --set global.hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,http}" \ --set global.prometheus.enabled=true \ --set global.operatorPrometheus.enabled=true \ --set global.hubble.ui.enabled=true
https://pan.baidu.com/s/1gRVM37RjFyEebBfQ-1MyJQ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [root@master01 ~]# kubectl get pods --all-namespaces -w NAMESPACE NAME READY STATUS RESTARTS AGE kube-system cilium-4qs42 1/1 Running 0 14m kube-system cilium-5v9xc 1/1 Running 0 14m kube-system cilium-gw5nh 1/1 Running 0 14m kube-system cilium-node-init-4cvlf 1/1 Running 0 14m kube-system cilium-node-init-4jxhb 1/1 Running 0 14m kube-system cilium-node-init-5m5ns 1/1 Running 0 14m kube-system cilium-node-init-klw8c 1/1 Running 0 14m kube-system cilium-node-init-kvgwp 1/1 Running 0 14m kube-system cilium-node-init-sc2wb 1/1 Running 0 14m kube-system cilium-nz8wc 1/1 Running 0 14m kube-system cilium-operator-657978fb5b-j8bzv 1/1 Running 0 14m kube-system cilium-p6mzq 1/1 Running 0 14m kube-system cilium-xchz5 1/1 Running 0 14m kube-system coredns-84b99c4749-bb54k 1/1 Running 0 29m kube-system coredns-84b99c4749-q9z4r 1/1 Running 0 29m kube-system etcd-master01 1/1 Running 0 29m kube-system etcd-master02 1/1 Running 0 26m kube-system etcd-master03 1/1 Running 0 26m kube-system hubble-relay-55c5cbdfcb-m4bx6 1/1 Running 0 11m kube-system hubble-ui-66fdcdc6d-czz8k 1/1 Running 0 14m kube-system kube-apiserver-master01 1/1 Running 0 29m kube-system kube-apiserver-master02 1/1 Running 0 27m kube-system kube-apiserver-master03 1/1 Running 0 25m kube-system kube-controller-manager-master01 1/1 Running 1 29m kube-system kube-controller-manager-master02 1/1 Running 0 27m kube-system kube-controller-manager-master03 1/1 Running 0 25m kube-system kube-proxy-9k98m 1/1 Running 0 26m kube-system kube-proxy-ddhd4 1/1 Running 0 25m kube-system kube-proxy-dqd45 1/1 Running 0 25m kube-system kube-proxy-jbwtg 1/1 Running 0 27m kube-system kube-proxy-mj75f 1/1 Running 0 29m kube-system kube-proxy-xjpkd 1/1 Running 0 25m kube-system kube-scheduler-master01 1/1 Running 1 29m kube-system kube-scheduler-master02 1/1 Running 0 27m kube-system kube-scheduler-master03 1/1 Running 0 25m
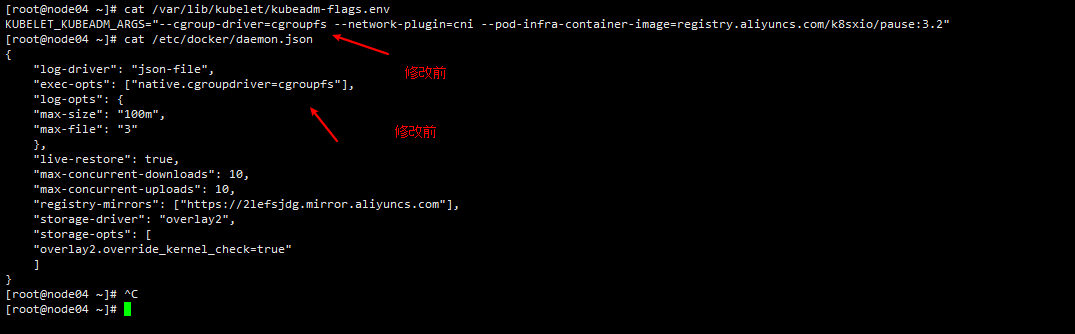
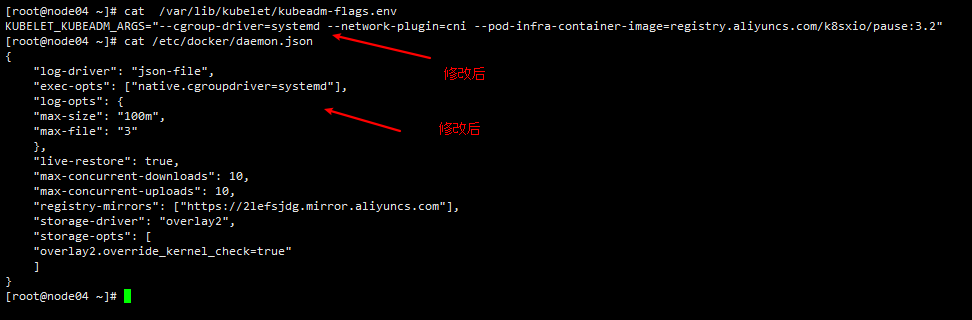
由于kubeadm默认使用cgoupfs,官方推荐用systemd,所有节点都得进行检查和修改成systemd,然后重启docker,kubelelt
1 2 3 vim /var/lib/kubelet/kubeadm-flags.env vim /etc/docker/daemon.json
1 2 systemctl restart docker systemctl restart kubelet
1 2 3 4 5 6 7 8 [root@master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready master 37m v1.18.5 master02 Ready master 34m v1.18.5 master03 Ready master 33m v1.18.5 node01 Ready node 19m v1.18.5 node02 Ready node 19m v1.18.5 node03 Ready node 19m v1.18.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 cat<<EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: nginx ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx spec: selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 --- apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - name: busybox image: busybox:1.28.4 command: - sleep - "3600" imagePullPolicy: IfNotPresent restartPolicy: Always EOF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master01 ~]# kubectl get all -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/busybox 1/1 Running 0 73s 10.244.186.194 node03 <none> <none> pod/nginx-5c559d5697-24zck 1/1 Running 0 73s 10.244.186.193 node03 <none> <none> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 42m <none> service/nginx ClusterIP 10.111.219.3 <none> 80/TCP 73s app=nginx NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/nginx 1/1 1 1 73s nginx nginx:alpine app=nginx NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR replicaset.apps/nginx-5c559d5697 1 1 1 73s nginx nginx:alpine app=nginx,pod-template-hash=5c559d5697
1 2 3 4 5 6 [root@master01 ~]# kubectl exec -ti busybox -- nslookup kubernetes Server: 10.96.0.10 Address: 10.96.0.10#53 Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master01 ~]# curl 10.244.186.193 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@master01 ~]# curl 10.111.219.3 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
1 2 3 4 5 6 [root@master01 ~]# kubectl exec -ti busybox -- nslookup nginx Server: 10.96.0.10 Address: 10.96.0.10#53 Name: nginx.default.svc.cluster.local Address: 10.111.219.3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@node01 ~]# ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.96.0.1:443 rr -> 192.168.33.101:6443 Masq 1 1 0 -> 192.168.33.102:6443 Masq 1 0 0 -> 192.168.33.103:6443 Masq 1 1 0 TCP 10.96.0.10:53 rr -> 10.244.140.65:53 Masq 1 0 0 -> 10.244.140.67:53 Masq 1 0 0 TCP 10.96.0.10:9153 rr -> 10.244.140.65:9153 Masq 1 0 0 -> 10.244.140.67:9153 Masq 1 0 0 TCP 10.111.219.3:80 rr -> 10.244.186.193:80 Masq 1 0 0 UDP 10.96.0.10:53 rr -> 10.244.140.65:53 Masq 1 0 0 -> 10.244.140.67:53 Masq 1 0 0
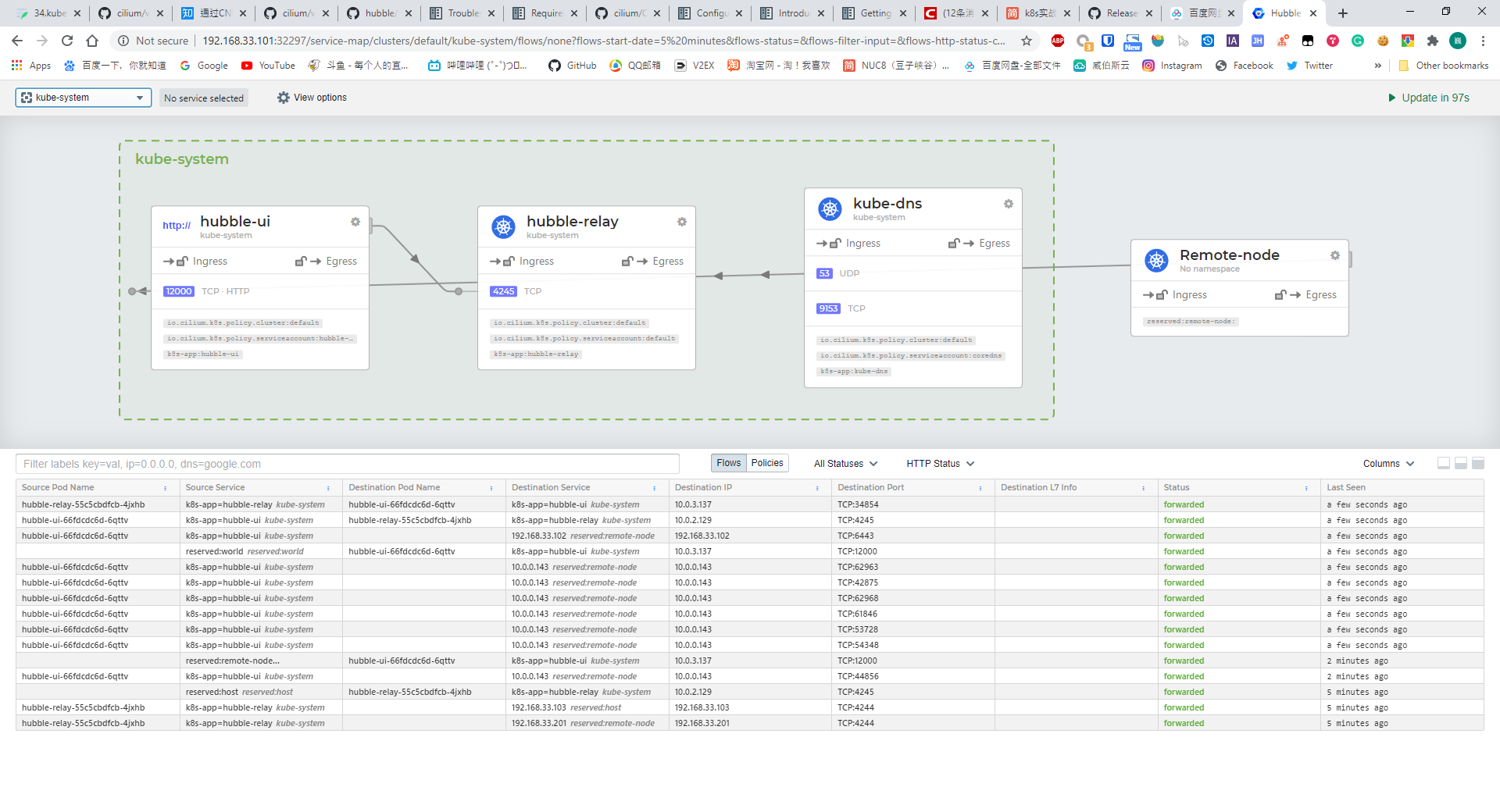
Cilium 强大之处就是提供了简单高效的网络可视化功能,它是通过 Hubble 组件完成的。Cilium 在 1.7 版本后推出并开源了 Hubble ,它是专门为网络可视化设计,能够利用 Cilium 提供的 eBPF 数据路径,获得对 Kubernetes 应用和服务的网络流量的深度可见性。
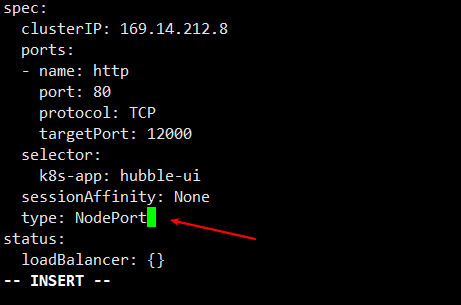
1 kubectl edit svc -n kube-system hubble-ui
https://www.yuque.com/xiaowei-trt7k/tw/ah0ls0