deployment.yaml文件详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
| apiVersion: extensions/v1beta1 #接口版本
kind: Deployment #接口类型
metadata:
name: cango-demo #Deployment名称
namespace: cango-prd #命名空间
labels:
app: cango-demo #标签
spec: #specification of the resource content 指定该资源的内容
replicas: 3
strategy:
rollingUpdate: ##由于replicas为3,则整个升级,pod个数在2-4个之间
maxSurge: 1 #滚动升级时会先启动1个pod
maxUnavailable: 1 #滚动升级时允许的最大Unavailable的pod个数
template:
metadata:
labels:
app: cango-demo #模板名称必填
sepc: #定义容器模板,该模板可以包含多个容器
containers:
- name: cango-demo #镜像名称
image: swr.cn-east-2.myhuaweicloud.com/cango-prd/cango-demo:0.0.1-SNAPSHOT #镜像地址
command: [ "/bin/sh","-c","cat /etc/config/path/to/special-key" ] #启动命令
args: #启动参数
- '-storage.local.retention=$(STORAGE_RETENTION)'
- '-storage.local.memory-chunks=$(STORAGE_MEMORY_CHUNKS)'
- '-config.file=/etc/prometheus/prometheus.yml'
- '-alertmanager.url=http://alertmanager:9093/alertmanager'
- '-web.external-url=$(EXTERNAL_URL)'
#如果command和args均没有写,那么用Docker默认的配置。
#如果command写了,但args没有写,那么Docker默认的配置会被忽略而且仅仅执行.yaml文件的command(不带任何参数的)。
#如果command没写,但args写了,那么Docker默认配置的ENTRYPOINT的命令行会被执行,但是调用的参数是.yaml中的args。
#如果如果command和args都写了,那么Docker默认的配置被忽略,使用.yaml的配置。
imagePullPolicy: IfNotPresent #如果不存在则拉取
livenessProbe: #表示container是否处于live状态。如果LivenessProbe失败,LivenessProbe将会通知kubelet对应的container不健康了。随后kubelet将kill掉container,并根据RestarPolicy进行进一步的操作。默认情况下LivenessProbe在第一次检测之前初始化值为Success,如果container没有提供LivenessProbe,则也认为是Success;
httpGet:
path: /health #如果没有心跳检测接口就为/
port: 8080
scheme: HTTP
initialDelaySeconds: 60 ##启动后延时多久开始运行检测
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /health #如果没有心跳检测接口就为/
port: 8080
scheme: HTTP
initialDelaySeconds: 30 ##启动后延时多久开始运行检测
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
resources: ##CPU内存限制
requests:
cpu: 2
memory: 2048Mi
limits:
cpu: 2
memory: 2048Mi
env: ##通过环境变量的方式,直接传递pod=自定义Linux OS环境变量
- name: LOCAL_KEY #本地Key
value: value
- name: CONFIG_MAP_KEY #局策略可使用configMap的配置Key,
valueFrom:
configMapKeyRef:
name: special-config #configmap中找到name为special-config
key: special.type #找到name为special-config里data下的key
ports:
- name: http
containerPort: 8080 #对service暴露端口
volumeMounts: #挂载volumes中定义的磁盘
- name: log-cache
mount: /tmp/log
- name: sdb #普通用法,该卷跟随容器销毁,挂载一个目录
mountPath: /data/media
- name: nfs-client-root #直接挂载硬盘方法,如挂载下面的nfs目录到/mnt/nfs
mountPath: /mnt/nfs
- name: example-volume-config #高级用法第1种,将ConfigMap的log-script,backup-script分别挂载到/etc/config目录下的一个相对路径path/to/...下,如果存在同名文件,直接覆盖。
mountPath: /etc/config
- name: rbd-pvc #高级用法第2中,挂载PVC(PresistentVolumeClaim)
#使用volume将ConfigMap作为文件或目录直接挂载,其中每一个key-value键值对都会生成一个文件,key为文件名,value为内容,
volumes: # 定义磁盘给上面volumeMounts挂载
- name: log-cache
emptyDir: {}
- name: sdb #挂载宿主机上面的目录
hostPath:
path: /any/path/it/will/be/replaced
- name: example-volume-config # 供ConfigMap文件内容到指定路径使用
configMap:
name: example-volume-config #ConfigMap中名称
items:
- key: log-script #ConfigMap中的Key
path: path/to/log-script #指定目录下的一个相对路径path/to/log-script
- key: backup-script #ConfigMap中的Key
path: path/to/backup-script #指定目录下的一个相对路径path/to/backup-script
- name: nfs-client-root #供挂载NFS存储类型
nfs:
server: 10.42.0.55 #NFS服务器地址
path: /opt/public #showmount -e 看一下路径
- name: rbd-pvc #挂载PVC磁盘
persistentVolumeClaim:
claimName: rbd-pvc1 #挂载已经申请的pvc磁盘
|
Pod yaml文件详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| # yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
|
Service yaml文件详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
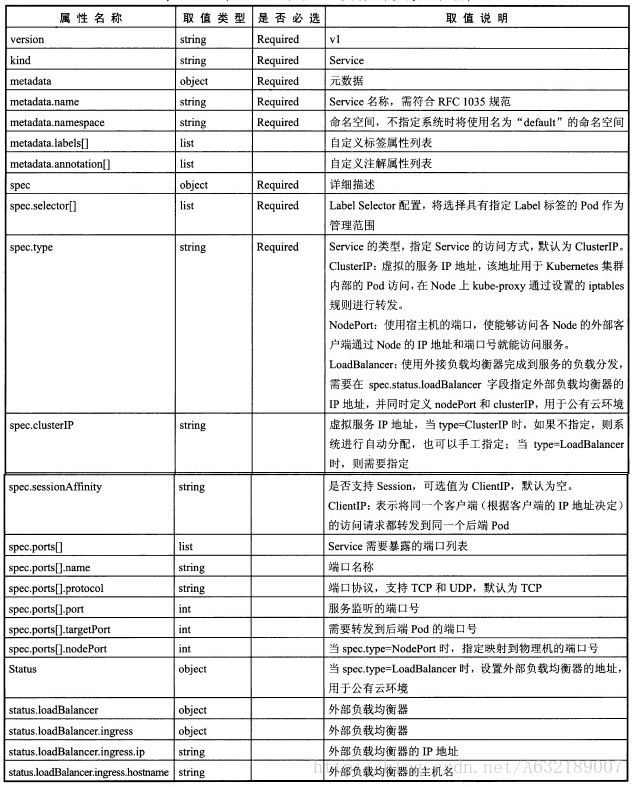
| apiVersion: v1
kind: Service
matadata: #元数据
name: string #service的名称
namespace: string #命名空间
labels: #自定义标签属性列表
- name: string
annotations: #自定义注解属性列表
- name: string
spec: #详细描述
selector: [] #label selector配置,将选择具有label标签的Pod作为管理
#范围
type: string #service的类型,指定service的访问方式,默认为
#clusterIp
clusterIP: string #虚拟服务地址
sessionAffinity: string #是否支持session
ports: #service需要暴露的端口列表
- name: string #端口名称
protocol: string #端口协议,支持TCP和UDP,默认TCP
port: int #服务监听的端口号
targetPort: int #需要转发到后端Pod的端口号
nodePort: int #当type = NodePort时,指定映射到物理机的端口号
status: #当spce.type=LoadBalancer时,设置外部负载均衡器的地址
loadBalancer: #外部负载均衡器
ingress: #外部负载均衡器
ip: string #外部负载均衡器的Ip地址值
hostname: string #外部负载均衡器的主机名
|
目前kubernetes提供了两种负载分发策略:RoundRobin和SessionAffinity
RoundRobin:轮询模式,即轮询将请求转发到后端的各个Pod上
SessionAffinity:基于客户端IP地址进行会话保持的模式,第一次客户端访问后端某个Pod,之后的请求都转发到这个Pod上
默认是RoundRobin模式
在某些场景中,开发人员希望自己控制负载均衡的策略,不使用Service提供的默认负载,kubernetes通过Headless Service的概念来实现。不给Service设置ClusterIP(无入口IP地址):
1
2
3
4
5
6
7
8
9
10
11
12
| apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx
|
有时候,一个容器应用提供多个端口服务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8080
targetPort: 8080
name: web
- port: 8005
targetPort: 8005
name: management
selector:
app: webapp
|
为不同的应用分配各自的端口。
另一个例子是两个端口使用了不同的4层协议,即TCP或UDP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 169.169.0.100
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
|
集群外部访问Pod或Service
为了让外部客户端可以访问这些服务,可以将Pod或者Service的端口号映射到宿主主机,使得客户端应用能够通过物理机访问容器应用。
将容器应用的端口号映射到物理机
通过设置容器级别的hostPort,将容器应用的端口号映射到物理机上:
pod-hostport.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
| apiVersion: v1
kind: Pod
metadata:
name: webapp
labels:
app: webapp
spec:
containers:
- name: webapp
image: tomcat
ports:
- containerPort: 8080
hostPort:8081
|
创建这个Pod:
1
| kubectl create -f pod-hostnetwork.yaml
|
通过物理机的IP地址和8080端口访问Pod的容器服务:
将Service的端口号映射到物理机
通过设置nodePort映射到物理机,同时设置Service的类型为NodePort:
webapp-svc-nodeport.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
| apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 8081
selector:
app: webapp
|
创建这个Service:
1
| kubectl create -f webapp-svc-nodeport.yaml
|
通过物理机的IP和端口访问:
ingress.yaml详解
通常情况下,service和pod仅可在集群内部网络中通过IP地址访问。所有到达边界路由器的流量或被丢弃或被转发到其他地方。从概念上讲,可能像下面这样:
1
2
3
4
| internet
|
------------
[ Services ]
|
Ingress是授权入站连接到达集群服务的规则集合。
1
2
3
4
5
| internet
|
[ Ingress ]
--|-----|--
[ Services ]
|
你可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等。用户通过POST Ingress资源到API server的方式来请求ingress。 Ingress controller负责实现Ingress,通常使用负载平衡器,它还可以配置边界路由和其他前端,这有助于以HA方式处理流量。
Ingress Resource
最简化的Ingress配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec: # Ingress spec 中包含配置一个loadbalancer或proxy server
rules: # 的所有信息。最重要的是,它包含了一个匹配所有入站请求的规
- http: # 则列表。目前ingress只支持http规则。
paths:
- path: /testpath # 每条http规则包含以下信息:一个host配置项(比如
# for.bar.com,在这个例子中默认是*),path列表(比
# 如:/testpath),每个path都关联一个backend(比如
# test:80)。在loadbalancer将流量转发到backend之前,所有的
# 入站请求都要先匹配host和path。
backend:
serviceName: test # backend是一个service:port的组合。Ingress的流量被转发到
servicePort: 80 # 它所匹配的backend
|
Ingress类型
Kubernetes中已经存在一些概念可以暴露单个service,但是你仍然可以通过Ingress来实现,通过指定一个没有rule的默认backend的方式。
ingress.yaml定义文件:
1
2
3
4
5
6
7
8
| apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend:
serviceName: testsvc
servicePort: 80
|
使用kubectl create -f命令创建,然后查看ingress:
1
2
3
| $ kubectl get ing
NAME RULE BACKEND ADDRESS
test-ingress - testsvc:80 107.178.254.228
|
107.178.254.228就是Ingress controller为了实现Ingress而分配的IP地址。RULE列表示所有发送给该IP的流量都被转发到了BACKEND所列的Kubernetes service上。
简单展开
如前面描述的那样,kubernete pod中的IP只在集群网络内部可见,我们需要在边界设置一个东西,让它能够接收ingress的流量并将它们转发到正确的端点上。这个东西一般是高可用的loadbalancer。使用Ingress能够允许你将loadbalancer的个数降低到最少,例如,假如你想要创建这样的一个设置:
1
2
| foo.bar.com -> 178.91.123.132 -> / foo s1:80
/ bar s2:80
|
你需要一个这样的ingress:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
|
使用kubectl create -f创建完ingress后:
1
2
3
4
5
6
| $ kubectl get ing
NAME RULE BACKEND ADDRESS
test -
foo.bar.com
/foo s1:80
/bar s2:80
|
只要服务(s1,s2)存在,Ingress controller就会将提供一个满足该Ingress的特定loadbalancer实现。 这一步完成后,您将在Ingress的最后一列看到loadbalancer的地址。
基于名称的虚拟主机
Name-based的虚拟主机在同一个IP地址下拥有多个主机名。
1
2
3
| foo.bar.com --| |-> foo.bar.com s1:80
| 178.91.123.132 |
bar.foo.com --| |-> bar.foo.com s2:80
|
下面这个ingress说明基于Host header的后端loadbalancer的路由请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
|
默认backend:一个没有rule的ingress,如前面章节中所示,所有流量都将发送到一个默认backend。你可以用该技巧通知loadbalancer如何找到你网站的404页面,通过制定一些列rule和一个默认backend的方式。如果请求header中的host不能跟ingress中的host匹配,并且/或请求的URL不能与任何一个path匹配,则流量将路由到你的默认backend。
转自 https://www.kubernetes.org.cn/1885.html